Generating image data with g.t. saliency maps#
Let’s explore the ‘seneca’ method for generating artificial images with available ground truth saliency maps. It was presented in Evaluating local explanation methods on ground truth, Riccardo Guidotti, 2021, and although the original intention of the paper was not to present an artificial data generator, it can serve our purpose.
[1]:
import matplotlib.pyplot as plt
import numpy as np
import teex
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
from math import floor
1. Generating synthetic images#
Let’s generate artificial image data with the ‘seneca’ method. In this case, the generated images are composed of squared cells of a fixed size and randomly colored as (almost) Red, Green or Blue. A number of these images contain a randomly generated pattern such that the ones that do so are labeled as ‘1’ and the ones that are not are labeled as ‘0’. If an image contains the pattern, then the ground truth explanation is a binary mask of the same dimensions where the pattern is highlighted. The user can control:
Image width and height, in pixels
Image cell width and height, in pixels and divisor of image width and height
The proportion of the image that should be filled with cells (fillPct)
Pattern height and width, in pixels. The number of pixels the randomly generated pattern will take (divisor of image width and height). The previous parameter ‘fillPct’ also specifies the number of cells filled in the pattern.
The percentage of images that contain the pattern ‘patternProp’
colorDev: [0, 0.5] If 0, each cell will be completely red, green or blue. The greater (max 0.5), the more mixed will colored channels be. Adds complexity to the task of classification.
[3]:
from teex.saliencyMap.data import SenecaSM
nSamples = 100
randomState = 8
imageH, imageW = 32, 32
patternH, patternW = 16, 16
cellH, cellW = 4, 4
patternProp = 0.5
fillPct = 0.4
colorDev = 0.1
dataGen = SenecaSM(nSamples=nSamples, imageH=imageH, imageW=imageW,
patternH=patternH, patternW=patternW,
cellH=cellH, cellW=cellW, patternProp=patternProp,
fillPct=fillPct, colorDev=colorDev, randomState=randomState)
X, y, exps = dataGen[:]
pat = dataGen.pattern
X contains the generated images, y the labels, exps the ground truth explanations and pat the exact pattern contained by the images.
2. Exploring the images#
Some of the generated images contain the following pattern:
[4]:
plt.imshow(pat)
[4]:
<matplotlib.image.AxesImage at 0x142066cd0>

For example, the first one, which is labeled as
[5]:
print(y[0])
plt.imshow(X[0])
1
[5]:
<matplotlib.image.AxesImage at 0x1424ee7f0>

contains it
[6]:
plt.imshow(exps[0])
[6]:
<matplotlib.image.AxesImage at 0x142b78a60>

for a more clear view:
[7]:
def plt_imgs(p, img, exp):
fig, axs = plt.subplots(1, 3)
axs[0].imshow(p)
axs[0].set_title('Pattern')
axs[1].imshow(img)
axs[1].set_title('Generated image')
axs[2].imshow(exp)
axs[2].set_title('Explanation')
plt_imgs(pat, X[0], exps[0])

Not all images have the pattern in the same position:
[8]:
plt_imgs(pat, X[6], exps[6])

We can generate images with another pattern by changing the random state
[10]:
dataGen = SenecaSM(nSamples=100, imageH=imageH, imageW=imageW,
patternH=patternH, patternW=patternW,
cellH=cellH, cellW=cellW, patternProp=patternProp,
fillPct=fillPct, colorDev=colorDev, randomState=7)
X, y, exps = dataGen[:]
pat = dataGen.pattern
plt_imgs(pat, X[1], exps[1])
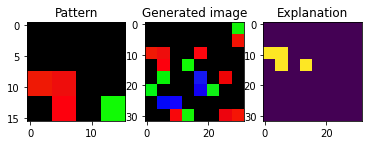
The images that do not contain a pattern have as explanation a black mask. Note that in order for the images to contain the pattern it must not only match the shape, but its colors too. We can check that we have the desired proportion of classes in the dataset:
[11]:
sum(y) / len(y) == patternProp
[11]:
True
We can also check how changing the parameter colorDev affects the coloring of the images
[12]:
dataGen = SenecaSM(nSamples=nSamples, imageH=imageH, imageW=imageW,
patternH=patternH, patternW=patternW,
cellH=cellH, cellW=cellW, patternProp=patternProp,
fillPct=fillPct, colorDev=0.5, randomState=randomState)
X, y, exps = dataGen[:]
pat = dataGen.pattern
plt_imgs(pat, X[1], exps[1])
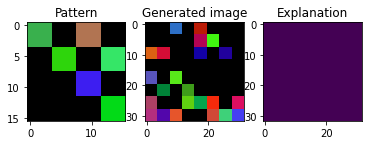
Indeed, the pattern and the cells that are filled in the images are the same, but the colors are different.
3. Exploring a white-box model#
The ‘seneca’ method used to generate the artificial data in TAIAOexp can also return an underlying white-box model. In the case of the image data, the model can recognize if the generated pattern is contained within an observation by performing a linear scan. The models implement .fit, .predict and .predict_proba methods in order for them to easily work with explainability frameworks. We can retrieve the whitebox model by setting the parameter ‘returnModel’ to True when generating the data.
[13]:
dataGen = SenecaSM(nSamples=100, imageH=imageH, imageW=imageW,
patternH=patternH, patternW=patternW,
cellH=cellH, cellW=cellW, patternProp=patternProp,
fillPct=fillPct, colorDev=0.5, randomState=7)
X, y, exps = dataGen[:]
pat = dataGen.pattern
model = dataGen.transparentModel # the underlying transparent model
[14]:
model
[14]:
<teex.saliencyMap.data.TransparentImageClassifier at 0x142e7fb50>
[15]:
model.predict(X[:5])
[15]:
[1, 1, 0, 0, 0]
[16]:
model.predict_proba(X[:5])
[16]:
[[0.0, 1.0], [0.0, 1.0], [1.0, 0.0], [1.0, 0.0], [1.0, 0.0]]
The model can also ‘explain’ instances dynamically:
[17]:
explanations = model.explain(X[:2])
fig, axs = plt.subplots(1, 2)
axs[1].imshow(explanations[0])
axs[1].set_title('Generated explanation')
axs[0].imshow(X[0])
axs[0].set_title('Corresponding image')
[17]:
Text(0.5, 1.0, 'Corresponding image')
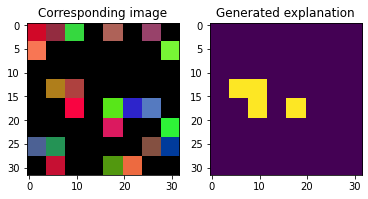
4. Loading Kahikata image data#
teex includes real datasets with available ground truth explanations. For example, the Kahikatea dataset contains 519 images, and the task is to tell whether each observation contains Kahikatea trees or not. There are 232 positive observations and 287 negative ones.
In teex, the non-artificial datasets are implemented as classes, similarly to PyTorch. After instancing the class, the data itself will be downloaded if it has not been used before. Once done, one can slice it to obtain observations. Each observation contains the data point, the label and the ground truth explanation.
[ ]:
from teex.saliencyMap.data import Kahikatea
kahikateaData = Kahikatea()
kData, kLabels, kExps = kahikateaData[:]
[21]:
i = 0
fig, axs = plt.subplots(1, 2, figsize=(15,15))
axs[0].imshow(kData[i])
axs[0].set_title('Image')
axs[1].imshow(kExps[i])
axs[1].set_title('g.t. explanation')
[21]:
Text(0.5, 1.0, 'g.t. explanation')
